Empowering the Visually Impaired: A Leap Forward with Vision Transformers
January 8, 2024In the pursuit of creating a more inclusive world, our team has embarked on a groundbreaking project: the “Blind Assistance Image Recognition System.” This initiative represents a significant leap forward in assistive technology, aiming to transform the lives of visually impaired individuals by enabling them to understand and interact with their environment more effectively.
Revolutionizing Perception with ViT-GPT2 Integration
Our system harnesses the power of the Vision Transformer (ViT) and GPT-2, revolutionizing image interpretation. ViT dissects images into patches, analyzing them for a contextual understanding, while the encoder-decoder architecture of GPT-2 takes these insights and translates them into detailed descriptions. This synergy allows for a nuanced perception of the environment, moving beyond mere object identification to a comprehensive narrative of the scene, significantly enhancing the experience for visually impaired individuals. This integrated approach offers a more profound and contextual understanding than traditional methods, paving the way for a new era in assistive technology.

Key Advantages of Vision Transformers:
- Contextual Understanding: ViT’s attention mechanism focuses on pertinent parts of the image, ensuring a detailed and nuanced interpretation.
- Spatial Hierarchy: By employing positional encodings, ViT maintains the image’s spatial relationships, crucial for comprehensive scene understanding.
- Coherent Descriptions: Integrated with an advanced language model, ViT translates complex visual information into descriptive text that reflects the content and context accurately.
Link to the model: nlpconnect/vit-gpt2-image-captioning · Hugging Face
Outshining Traditional Methods
The choice to employ ViT over multiple CNNs wasn’t incidental. Traditional CNNs, while effective, offer a fragmented understanding of scenes. ViT, in contrast, ensures that the generated descriptions are not just a collection of labels but a coherent narrative, enhancing the user’s comprehension and interaction with their surroundings.
| Traditional CNNs Output | ViT Output |
|---|---|
| Object: Car (x1,y1,x2,y2), Tree (x3,y3,x4,y4) | A red car parked under a large oak tree. |
| Object: Person (x5,y5,x6,y6), Dog (x7,y7,x8,y8) | A person walking their dog along the riverside. |
| Object: Bicycle (x9,y9,x10,y10), Fence (x11,y11,x12,y12) | A bicycle leaning against a wooden fence. |
| Object: Bench (x13,y13,x14,y14), Pond (x15,y15,x16,y16) | A bench overlooking a serene pond in the park. |
Enriching Understanding with Advanced Text-to-Speech
To further enhance the system’s utility, we’ve integrated an advanced Text-to-Speech (TTS) model. This component takes the descriptive text generated from the image recognition process and converts it into spoken words, providing an auditory representation of the visual data. This feature is crucial for visually impaired users, as it translates the detailed visual descriptions into a format they can easily understand and interact with.
Link to the TTS model: coqui/XTTS-v2 · Hugging Face

Real-World Impact and Future Directions
This system isn’t just a prototype; it’s a tool for empowerment. By providing visually impaired individuals with a more nuanced and holistic understanding of their environment, we’re opening up new avenues for them to navigate and interact with the world. Initially deployed on smartphones, future versions may include wearable devices, further integrating this technology into everyday life seamlessly
")
A Collaborative Journey
This project is not the end but the beginning of a journey. We invite academics, engineers, and the visually impaired community to engage with this technology, offer feedback, and suggest improvements. Together, we can refine this system and explore other areas where such sensory augmentation can significantly impact individuals' lives.
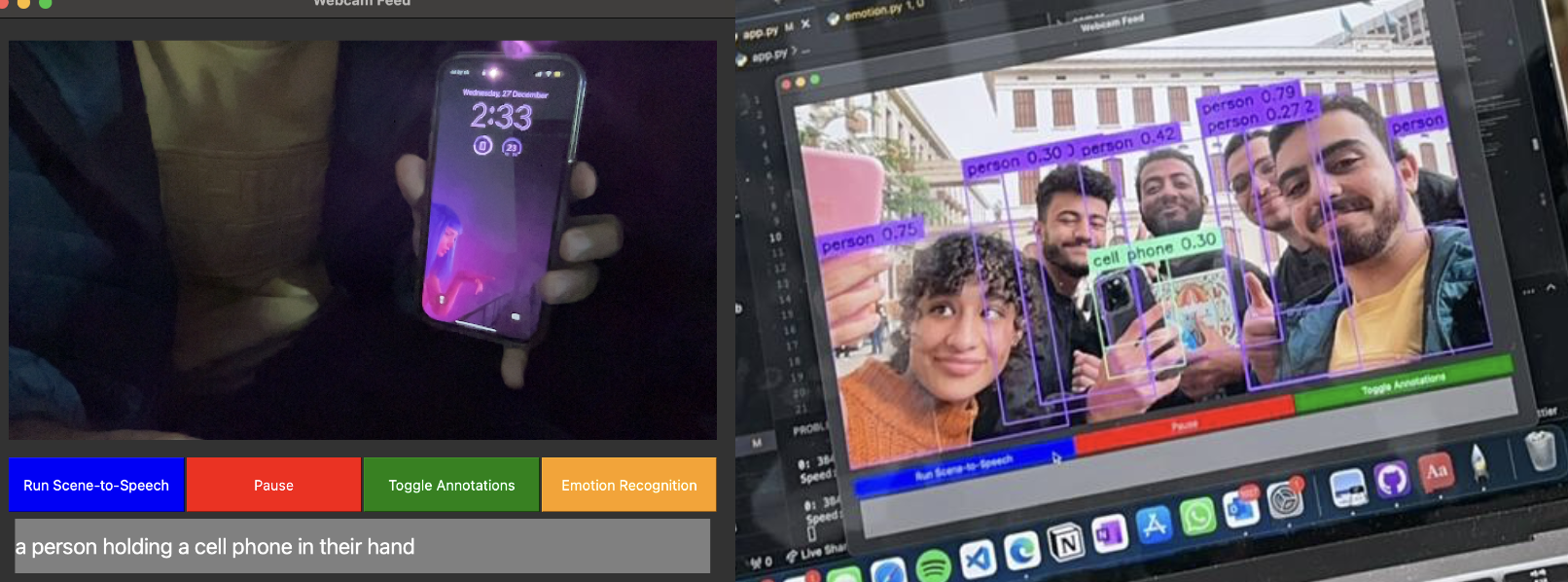
In conclusion, our “Blind Assistance Image Recognition System” represents an initial stride toward harnessing technology to aid those with visual impairments. While we are just students exploring the possibilities, this project, with its Vision Transformer foundation, aims to contribute positively by offering a tool that might enhance the perception and autonomy of visually impaired individuals. As we continue to learn and develop, we hope our work inspires further innovation and progress in this important field.
Team Members: Mohamed Nasser (Me), Maryam Moataz, Zeyad Mansour, Hassan Samy, Abdullah Saeed
Project link: https://github.com/mo-gaafar/blind-assistance-deep-learning